Prefect 도입기
히스토리
RDS에 쌓이는 데이터와 Firebase에서 받아오는 데이터를 BigQuery 데이터셋에 저장하고 BigQuery를 통해 데이터를 추출하고 Tableau나 엑셀을 이용해 시각화 또는 정리해서 분석을 하고 인사이트를 얻도록 하는 작업들을 하고 있습니다.
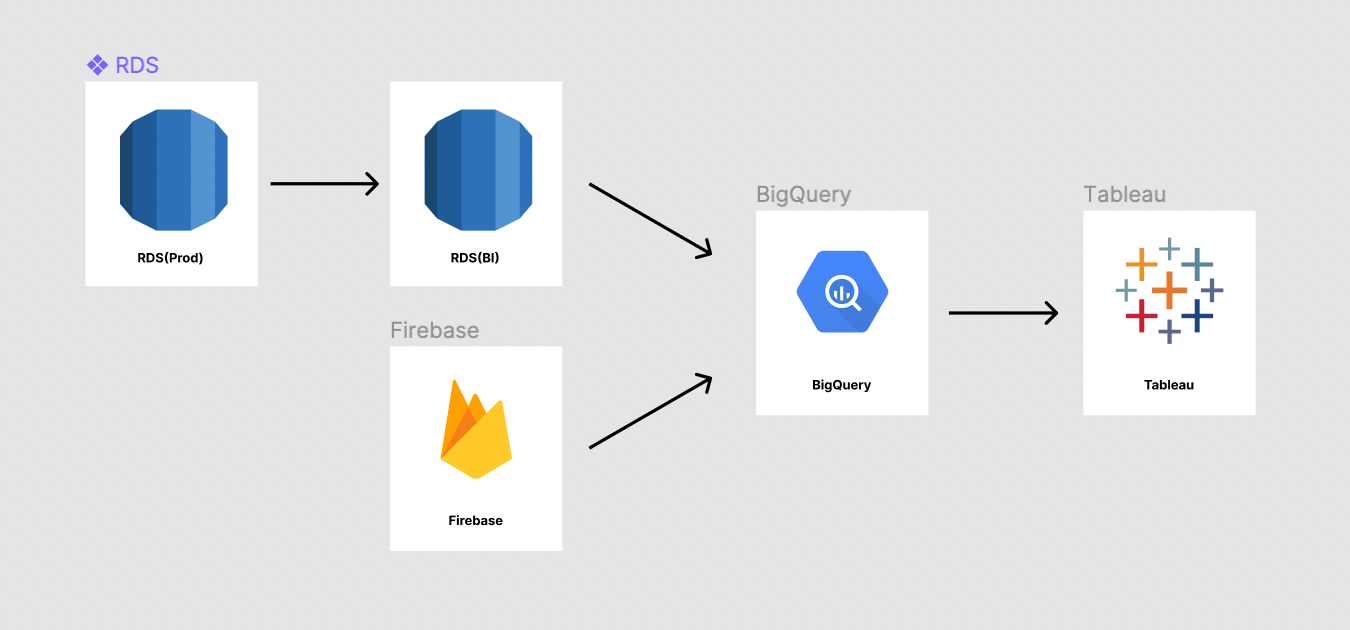
Firebase의 데이터를 BigQuery로 받아올 때 events_{날짜} 형식의 테이블로 데이터가 쌓입니다.
SELECT * FROM `analytics_000000000.events_20220408`
이런식으로 파이어베이스 이벤트 테이블에 쿼리하여 데이터를 확인할 수 있습니다.
처음에는 모든 테이블을 사용해도 쿼리 비용에 큰 부담이 없었는데요.
이벤트를 계속 추가하기도 하고 서비스가 성장하다 보니 이제는 하루에만 평균 30GB의 이벤트 데이터가 쌓이기 때문에 매번 모든 테이블을 사용하여 쿼리를 날리기엔 부담이 되었습니다.
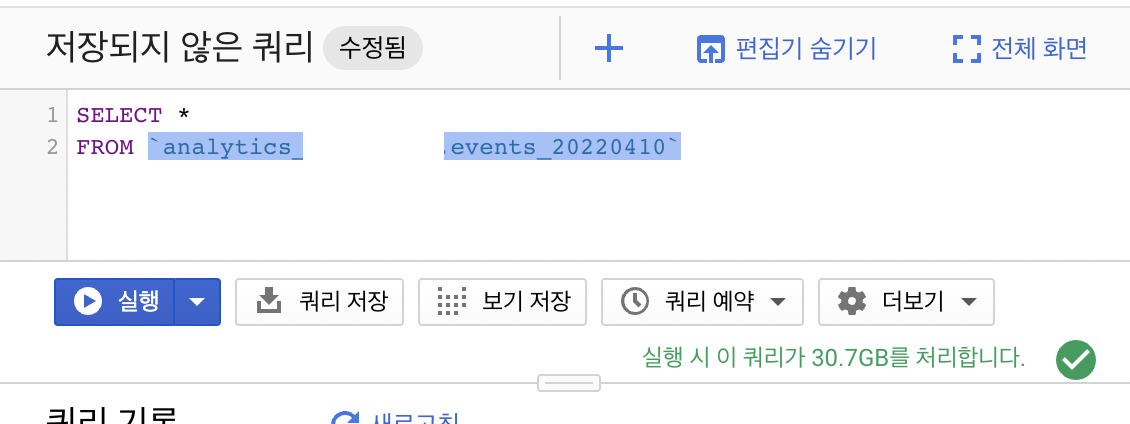
하루데이터가 30GB
그래서 주요 이벤트들(작품 읽기, 유입 등)에 대한 데이터들을 미리 정제? 해놓고 events 테이블에 직접 데이터를 조회하지 않아도 되도록 하여 빅쿼리 비용을 60% 이상(2019년 기준) 낮췄습니다. 미리 데이터를 한 번만 뽑아두면 해당 데이터를 사용할 땐 몇십 메가도 들지 않기때문에 아주 가벼워졌어요.
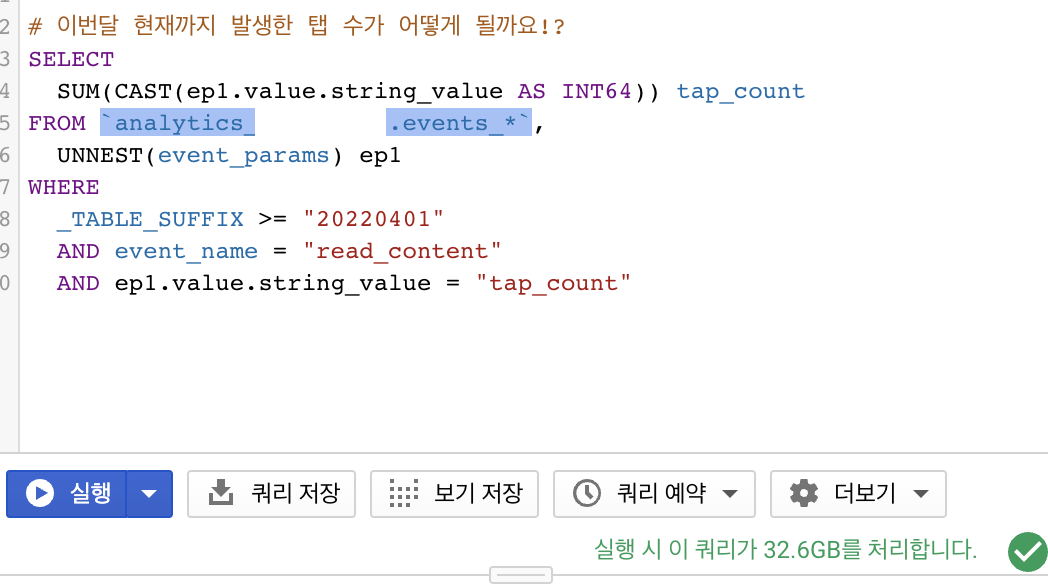
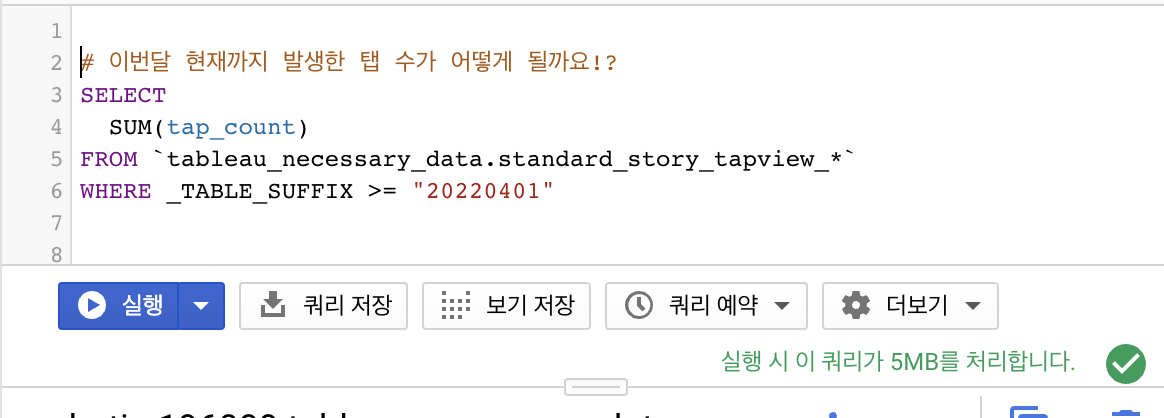
같은 결과물을 뽑지만 용량 차이가 어마어마합니다!
위의 작업들을 하기 위해 BigQuery의 예약 쿼리를 사용하였는데요. 예약쿼리는 설정한 시간에 설정해둔 쿼리를 자동으로 실행해주는 기능입니다. 매일 필요 데이터를 events_에서 뽑아 가볍게 사용할 수 있는 테이블로 만드는 작업을 예약 쿼리의 스케줄링을 통해 손쉽게 할 수 있었습니다!
그런데 이제 이 예약쿼리를 쓰면서 느끼던 아쉬운 점들이 생겨났습니다.
- 매번 접속시마다 엄청난 로딩 시간 (꽤 스트레스)
- 간혹 오류가 나서 플로우가 돌지 않기도 합니다. 실패시 이메일을 보내주는 기능이 있지만.. 이메일로 받기엔 좀 귀찮아 설정을 해두진 않았어요.
- 비슷한 쿼리를 특정 값만 다르게 해서 실행할 수 없습니다.(제가 덜 찾아본 걸 수도 있습니다!) 그래서 동일한 예약쿼리를 여러개 생성 및 관리 했어야 합니다.
- Firebase와 빅쿼리를 연동해두어 Firebase에 쌓인 이벤트들을 빅쿼리로 불러올 때 3일에 이어 데이터를 업데이트 해줍니다. 저는 매일매일 데이터가 업데이트 되길 원해서 쿼리를 짠 뒤 하루 전, 이틀 전, 사흘 전에 맞춰 쿼리를 수정하고 각각 예약 쿼리로 만들어 줍니다. 관리도 복잡해지고 쿼리를 수정하려 한다면 몇번씩 다시 콘솔로 가서 쿼리 업데이트를 해줘야 하는 아주 복잡한 플로우에 지쳤습니다..
- 사소하지만.. 스케줄링 시간을 한국 시간으로 업데이트해도 항상 일본 시간대로 맞춰져 있어요.
- 제가 없다면 이 스케줄 쿼리들을 관리할 사람이 있을까 싶었습니다. 타 회사의 데이터 팀들은 Airflow 같은 자동화 툴을 사용하고 있는 것 같았습니다.
위의 문제들로 종종 ETL툴을 도입을 해봐야지 하고 마음만 먹고 있었습니다.
그런데 회사에서 이제 글로벌 서비스를 런칭하면서 모든게 새로워졌고 글로벌 서비스의 데이터들을 관리하는 것 부터 시작해서 도입해 봐도 괜찮지 않을까 해서 도입을 하려고 합니다.
설치
Prefect에서 제공해주는 Cloud에 구축한 agent 서버를 붙이는 방향으로 진행합니다.
Prefect Cloud 가입을 진행하고 agent 연결을 위한 API Key를 발급합니다.
우측 상단의 Account Settings로 진입하여
Key를 생성해줍니다.

생성한 키를 기억해줍니다!
서버에서 세팅을 진행합니다.
Prefect를 설치합니다.
pip install prefect
pip install prefect["google"]
pip install prefect["github"]
BigQuery를 통해 쿼리 및 테이블을 생성할 것이고 Storage로 github를 사용할 것이기에 각 필요한 extra도 설치해 줍니다.
Agent 연결
Prefect Cloud에서 받아온 키를 통해 인증을 해줍니다.
prefect auth login --key [인증 키]
Prefect Cloud에 agent를 연결해줍니다.
prefect agent local start
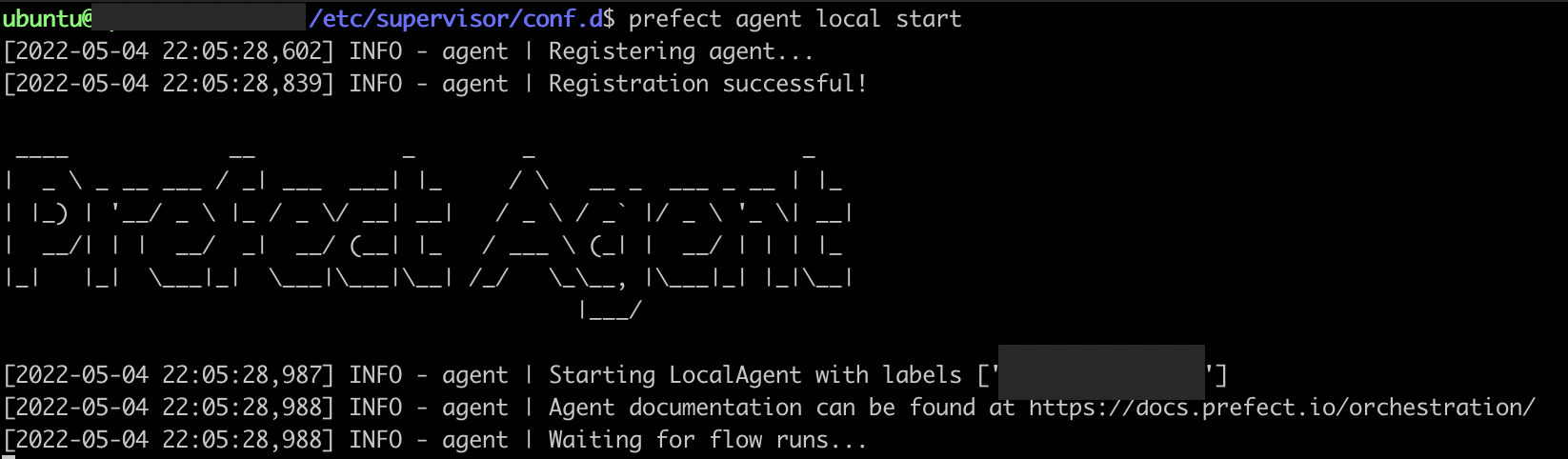 이렇게 켜지면 cloud에서 연결된 agent를 확인할 수 있습니다.
이렇게 켜지면 cloud에서 연결된 agent를 확인할 수 있습니다.
이제 Prefect Flow를 만들고 Cloud에 올려 실행하면 해당 agent를 통해 task가 돌아가게 됩니다.
GCP 인증
지금 그냥 BigQuery Task를 추가한다면 작동하지 않을 겁니다. BigQuery를 사용하기 위해서 GOOGLE_APPLICATION_CREDENTIALS를 설정해줘야 합니다.
GCP에서 인증가능한 json파일을 받아 서버에 저장해두고 GOOGLE_APPLICATION_CREDENTIALS 환경변수에 해당 파일의 경로를 넣어주면 인증을 통해 BigQuery Task를 쓸 수 있게 됩니다.
json파일을 받는 방법은 GCP 인증 해당 문서를 따라가면 될것 같습니다.
GitHub 인증
이제 로컬에서 코드를 작성해 github에 올리고 서버에서는 GitHub도 올려져 있는 코드를 사용할 수 있게 구성해보겠습니다. GitHub도 레포를 읽어오기 위해 인증이 필요합니다. GitHub 토큰 해당 문서를 따라가 토큰을 생성합니다.
서버에 prefect 환경을 구성했다면 ~/.prefect/ 폴더가 만들어져 있을 겁니다. config.toml이라는 새로운 파일을 만들고 아래와 같이 설정합니다.
[context.secrets]
GITHUB_ACCESS_TOKEN = "[토큰 입력]"
Supervisor 설정
그리고 agent가 백그라운드에서 항상 돌아갈 수 있도록 supervisor로 세팅을 해줍니다! supervisor를 다운받고 세팅 후에
/etc/supervisor/conf.d/prefect.conf 를 만들어 주고 아래 내용을 입력해줍니다.
[unix_http_server]
file=/tmp/supervisor.sock ; the path to the socket file
[supervisord]
loglevel=debug ; log level; default info; others: debug,warn,trace
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl]
serverurl=unix:///tmp/supervisor.sock ; use a unix:// URL for a unix socket
[program:prefect-agent]
command=/home/ubuntu/.local/bin/prefect agent local start -l production
user=ubuntu
environment=GOOGLE_APPLICATION_CREDENTIALS="/home/ubuntu/.keys/[key파일명].json"
environment에 GOOGLE_APPLICATION_CREDENTIALS를 넣어줘야 인식이 되는 것 같더라구요..!
“production” label로 인식하게 하기위해 -l production을 추가해 주었습니다.
Supervisor로 Agent 실행
sudo supervisorctl reread
sudo supervisorctl update
sudo supervisorctl restart prefect-agent
코드 작성
코드는 로컬에서 작성해주려고 합니다.
로컬에도 같은 환경으로 세팅해주고 코드를 작성합니다.
from prefect import Flow, task
from prefect.tasks.gcp.bigquery import BigQueryTask
from prefect.run_configs import UniversalRun
from prefect.storage import GitHub
from datetime import datetime, timedelta
def make_query():
return f"""
SELECT '1'
"""
storage = GitHub(
repo="[레포명]",
path="flows/test.py",
access_token_secret="GITHUB_ACCESS_TOKEN",
)
@task
def query():
query = make_query()
return BigQueryTask(
query=query,
name="test",
project="chatie-global-nam5",
dataset_dest="tableau_data",
table_dest="test",
job_config={"write_disposition": 'WRITE_TRUNCATE'}
).run()
with Flow("test", storage=storage) as flow:
query()
flow.register(project_name="BigqueryData")
storage 생성 부분에서 repo와 파일의 path를 알맞게 입력해주고
flow.register에서는 Cloud에 생성한 프로젝트 명을 입력해줍니다.
해당 파일을 GitHub에 push 해줍니다.
그리고 플로우를 등록해줍니다.
python flows/test.py
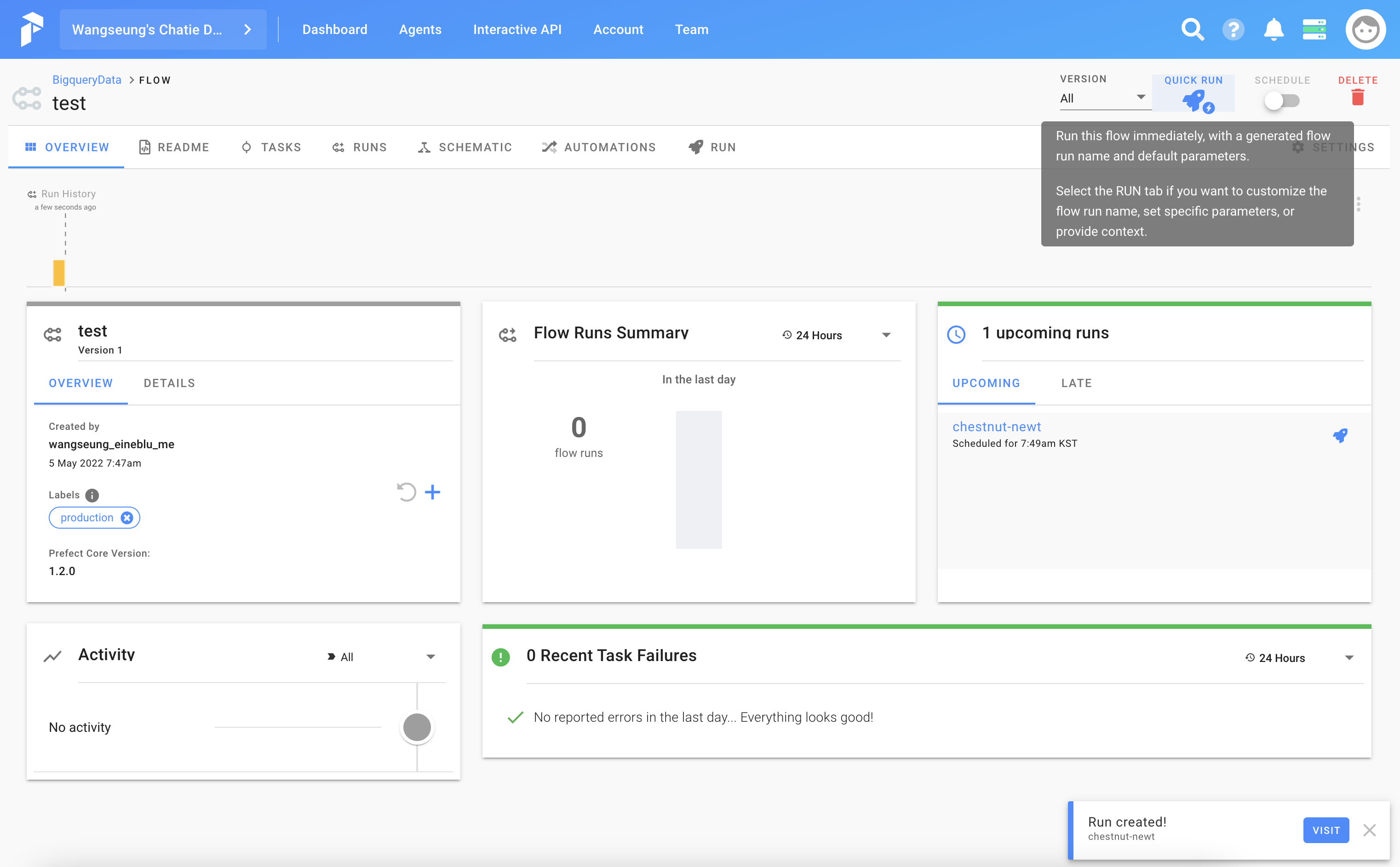
Cloud에서 등록된 flow를 확인할 수 있습니다.
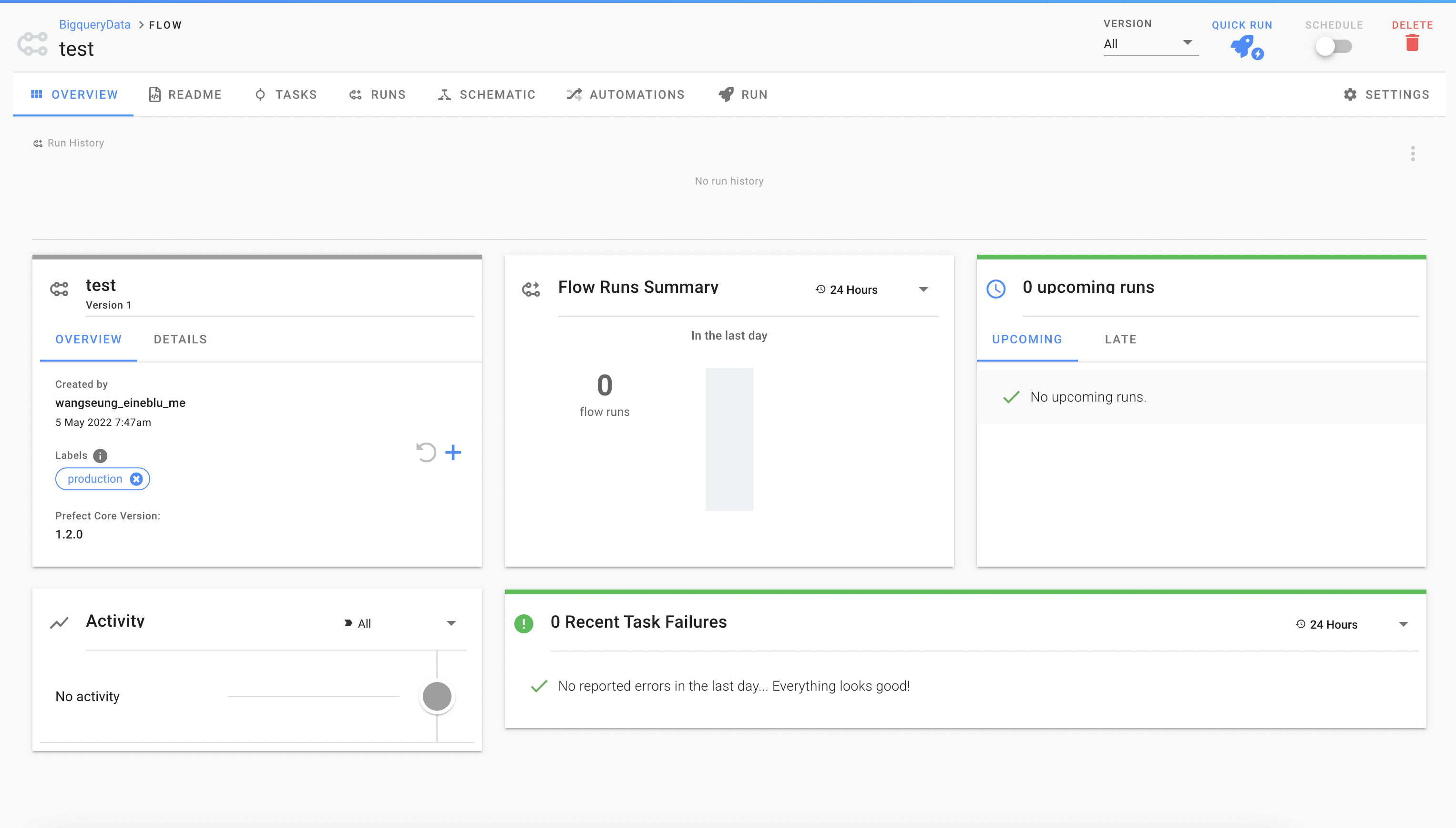
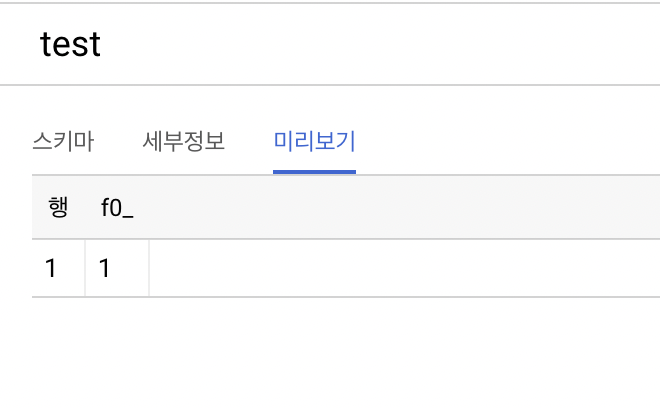
실행하여 빅쿼리에 생성된 결과도 확인할 수 있습니다.